





Wan2.2‑Animate 使用全攻略(ComfyUI/在线体验/参数建议)
文章摘要
神人GPT

1. Wan2.2‑Animate 是什么?
Wan2.2 是阿里云推出的新一代多模态视频生成模型,采用 MoE(Mixture of Experts)架构,强调影视级美学控制、复杂运动建模与更强的语义遵循;支持文生视频、图生视频与动作驱动等能力。
2. 哪里可以使用(推荐方式)

- 在线体验(免环境,官方):Hugging Face Space「Wan2.2‑Animate」可直接上传参考图与动作素材体验 Animation / Replacement 两种模式:https://huggingface.co/spaces/Wan-AI/Wan2.2-Animate
- 官方平台(wan.video):
- 官网与产品页(支持登录后使用“Try Now/Generate”入口):https://wan.video/welcome 与 https://create.wan.video/generate
- 官方技术博客(Wan‑Animate 两种模式与技术要点):https://wan.video/blog/wan2.2-animate
- 国内平台:ModelScope Studio 在线体验(更友好国内网络):https://www.modelscope.cn/studios/Wan-AI/Wan2.2-Animate
- 本地部署:使用 ComfyUI 最新版本,加载官方提供的 Wan2.2 原生模板(如 “Wan2.2 14B I2V”),按提示下载/配置对应权重后即可运行。
- 源码与权重:官方 GitHub 仓库提供 Wan2.2‑Animate 的开源代码、示例与说明,包含“角色动画/替换”的脚本与流程:https://github.com/Wan-Video/Wan2.2
- 社区在线与工作流:RunComfy 提供 Wan2.2 相关在线与工作流范例,便于快速试验与对照:https://www.runcomfy.com/playground/wan-ai/wan-2-2
3. Animate 两大实战玩法
Wan2.2‑Animate 更适合做“动作驱动类”的视频:给定一张或多张参考人物图,再提供动作参考视频,让目标角色按照参考动作自然运动,且尽量保持身份与表情一致。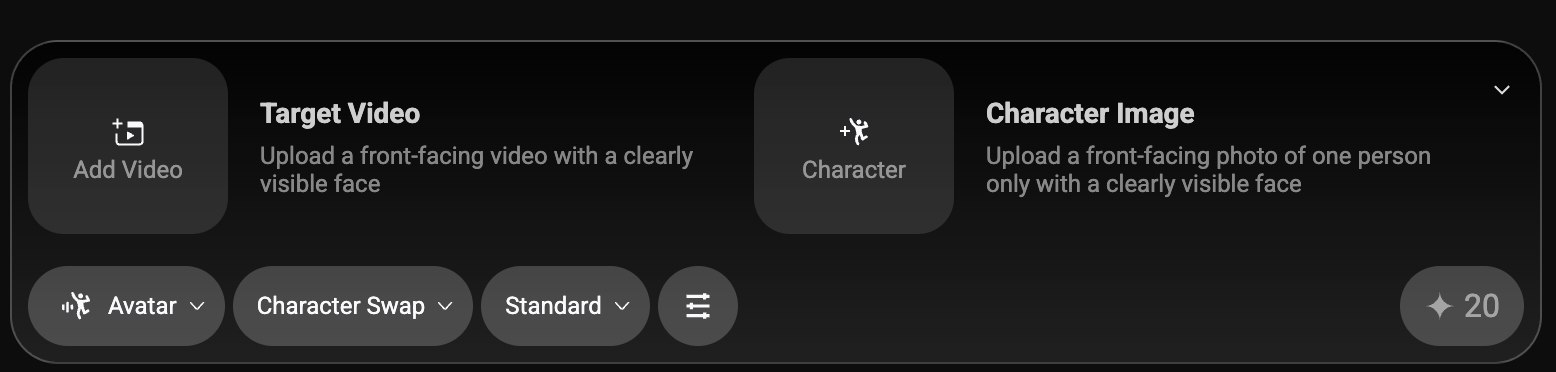
A. 角色动画(Animate)
- 准备:1 张清晰的人物/角色参考图 + 1 段动作参考视频(推荐与目标构图相近、光线稳定)。
- 流程思路:将参考图与动作视频传入 Animate 工作流 → 设定输出尺寸和时长 → 运行。
- 经验值:
- 参考图正脸清晰、无强遮挡,效果稳定。
- 参考视频运动不宜过快,光比大幅变化会带来抖动。
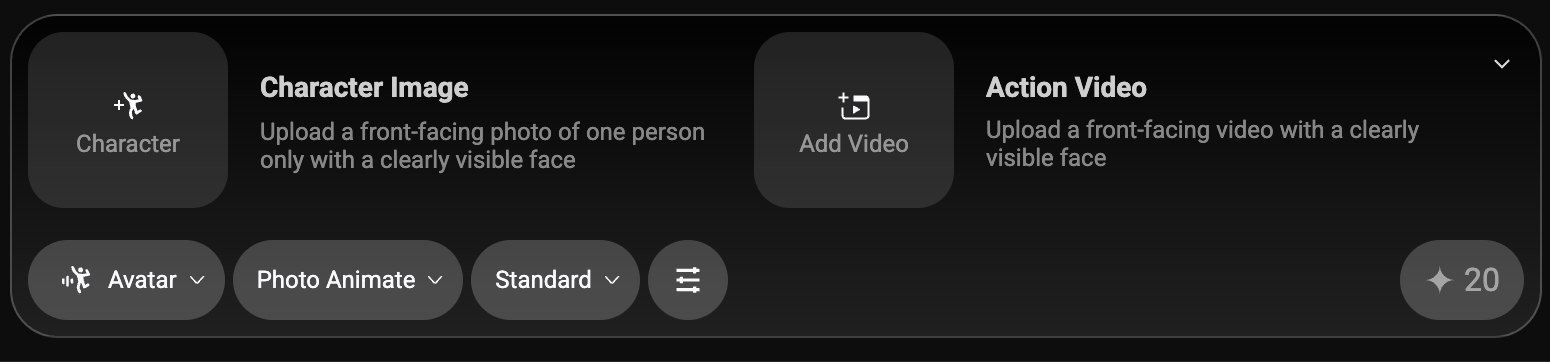
B. 角色替换(Replace)
- 用途:将视频中原人物替换为参考图人物,保留原视频的动作与镜头语言。
- 基本步骤:
- 提供待替换视频与参考人物图;
- 设置迭代次数/关键帧窗口等超参数;
- 导出结果并检查面部一致性与边缘融合;
- 调参建议:适度提高迭代与关键帧跨度可提升一致性,但会增加耗时;
2.1 在线体验到出片(一步步)
- 打开在线体验入口(Wan2.2‑Animate Space):https://huggingface.co/spaces/Wan-AI/Wan2.2-Animate
- 选择玩法模式:
- Animate(角色动画):上传 1 张人物/角色参考图 + 1 段动作参考视频,输出为“静态图随参考视频动作运动”的成片,身份与表情尽量一致。
- Replace(角色替换):上传 1 段原视频 + 1 张人物参考图,将原视频人物替换为参考人物,保留镜头与动作。
- 上传素材:参考图建议正脸清晰、无遮挡;动作视频尽量画面稳定、运动不宜过快。
- 参数建议:
- 分辨率先用 720p(或默认)试跑;长度 3–5s 快速预览;帧率 24/25fps。
- 若出现抖动/拉扯,缩短时长或更换光线更稳定的参考视频,再提升分辨率与时长。
- 点击运行并等待生成;如果边缘融合不理想,适当更换参考图或提高质量参数后重试。
2.2 从在线到本地复现(参数迁移指北)
- 在在线 Space 跑通并满意后,记录:输入分辨率(宽×高)、时长(秒/帧)、采样步数、提示词、模式(Animate/Replace)。
- 在本地 ComfyUI 打开 Wan2.2 模板后:
- 在 EmptyHunyuanLatentVideo(或相应尺寸节点)中设置相同分辨率与 length;
- 在 CLIP Text Encoder 粘贴相同的正/负向提示词;
- 在 KSampler 或相应采样节点设置一致的步数、CFG 等;
- 替换为相同的参考图与动作视频;
- 先以 720p/短时长复核效果,再逐步升到 1080p 及更长时长以节省调试时间。
4. 本地 ComfyUI 快速上手
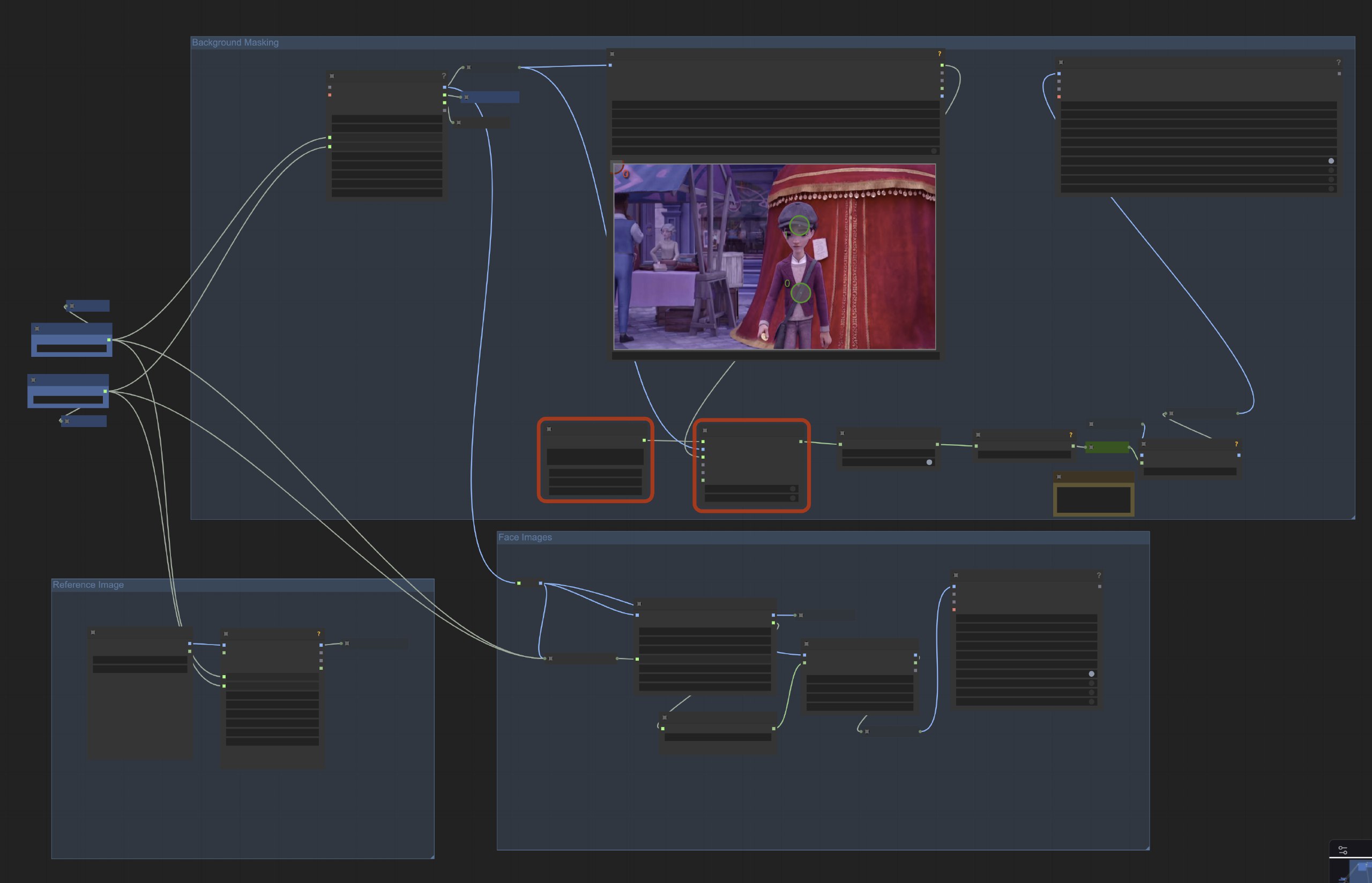
- 准备环境
- 更新 ComfyUI 至最新版(建议使用官方启动器或拉取最新源码)。
- 打开 ComfyUI,菜单:工作流 → 浏览模板 → 视频 → 选择 “Wan2.2 14B I2V”。
- 模型与文件放置(常见目录)
- Diffusion 模型:放入 ComfyUI/models/diffusion_models/
- 文本编码器(如 umt5_xxl…):放入 ComfyUI/models/text_encoders/
- VAE:放入 ComfyUI/models/vae/
- 加载失败时,检查节点上模型名与实际文件是否一致,或在节点列表里重新指向对应文件。
- 基础操作
- I2V(图生视频):在模板中替换输入图、修改正/负向提示词(CLIP Text Encoder 节点),设置分辨率与时长(EmptyHunyuanLatentVideo 等节点),点击 Run 生成。
- T2V(文生视频):清空输入图,仅保留提示词与尺寸配置;其他流程相同。
3.1 硬件/软件建议(概览)
- 显卡:5B 体量模型更显存友好(常见 8–12GB 可做 720p 快速预览),14B 体量更强调人物一致性与细节,需更高显存;如显存不足,优先降低分辨率/时长或改用 5B 体量。
- 运行库:建议 Torch ≥ 2.4;若使用官方推理代码,可结合 offload/混合精度降低显存压力。
3.2 Kijai 插件(进阶,可选)
- 插件:ComfyUI‑WanVideoWrapper
- 作用:提供更灵活的视频封装与最新研究优化,Wan 系列适配更新更快;适合希望深度定制的进阶用户。
- 安装:进入 ComfyUI/custom_nodes 目录后拉取仓库;或在 ComfyUI Manager 搜索安装。
3.3 使用官方仓库命令行推理(可选,适合批处理/自动化)
- 准备:
- 克隆官方仓库并安装依赖(确保 torch ≥ 2.4.0):
- 通过 Hugging Face 或 ModelScope 下载对应模型到本地目录。
- 示例:动画模式(Animation)/替换模式(Replacement)的预处理与生成
- 预处理(根据你的输入视频/参考图路径调整):
1 | python ./wan/modules/animate/preprocess/preprocess_data.py \ |
- 生成:
1 | python generate.py \ |
- 小贴士:遇到 OOM 可尝试启用 offload/混合精度或缩短时长与分辨率;多卡环境可按官方说明使用 FSDP/Ulysses 等并行策略。
5. 关键参数与建议
- 分辨率与时长:常见 720p(或按模板默认)先测试,跑通后再提升分辨率和时长;高分辨率对显存更敏感。
- 提示词:风格/光影/景别要明确,负向提示避免畸变与多余物体;可准备多套模板提示词复用。
- 参考素材:
- 人物图保证面部清晰、无遮挡、发型边缘干净;
- 动作视频尽量稳定、少运动模糊;
- 性能:显存吃紧时优先降低分辨率或时长,再考虑关闭高阶修复节点。
6. 常见问题排查
- 模型加载失败:检查节点绑定的文件名是否存在;若是首次运行,下载权重后将其放入正确目录并在节点上重新选择。
- 结果抖动/表情僵硬:
- 换一条更稳定的动作参考视频;
- 适度提高迭代/关键帧窗口;
- 参考图尽量与目标镜头角度接近。
- 色彩/光影不统一:增加或减弱风格/光影相关提示词;必要时做一次性后期色彩匹配。
7. 资源索引(建议收藏)
- 官方原生工作流与说明(ComfyUI):https://docs.comfy.org/zh-CN/tutorials/video/wan/wan2_2
- Wan2.2‑Animate 在线体验(Hugging Face Space):https://huggingface.co/spaces/Wan-AI/Wan2.2-Animate
- 官方开源仓库(含 Animate/Replace 脚本):https://github.com/Wan-Video/Wan2.2
- 官方主页与产品入口:
- 官网总览(含 Try Now):https://wan.video/welcome
- 生成入口(需登录):https://create.wan.video/generate
- 官方技术博客(Wan‑Animate 模式详解):https://wan.video/blog/wan2.2-animate
- 国内在线体验(ModelScope Studio):https://www.modelscope.cn/studios/Wan-AI/Wan2.2-Animate
- 社区工作流与教程(RunComfy):
- Wan2.2 Playground:
https://www.runcomfy.com/playground/wan-ai/wan-2-2 - VACE Fun(图像参考驱动动画)工作流:
https://www.runcomfy.com/comfyui-workflows/wan2-2-vace-fun-in-comfyui-image-animation-workflow - Fun Camera(相机运动)工作流:
https://www.runcomfy.com/comfyui-workflows/wan2-2-fun-camera-in-comfyui-cinematic-panning-zoom-rotation
- Wan2.2 Playground:
- 站内延伸阅读:
- 如何下载飞书只读文档?2025最新方法(支持Markdown/PDF导出):https://www.laogou717.com/2025/09/21/feishu-lark-document-download-guide-2025/


评论 ()


这是我的博客 / This is my Blog
神烦老狗
只有迎风,风筝才能飞得更高。




