





Qwen3‑Omni 使用全攻略(在线 Demo / Transformers / vLLM / 本地部署)
附:在线体验入口 & 本地部署教程(含 Ollama 路线可行性结论)
TL;DR(要点速览)
Qwen3‑Omni 是什么:阿里云通义团队发布的开源“端到端全模态”模型,原生理解文本/图片/音频/视频,并且可输出文本与语音(流式)。提供 Instruct / Thinking / Captioner 三个变体;许可证 Apache‑2.0。(Hugging Face)
在线入口:官方在 Hugging Face 上开了 Qwen3‑Omni Demo 与 Captioner Demo;模型卡含 QuickStart 与 vLLM/Transformers 用法;Qwen Chat 也可在线体验。(Hugging Face)
Ollama 路线结论:
- 目前无法直接用 Ollama 从 Hugging Face 部署 Qwen3‑Omni 全功能。Ollama 只能直接运行 GGUF 权重;而 Qwen3‑Omni 在 Hugging Face 以 safetensors 发布,提供的是 Transformers/vLLM 路线。(Hugging Face)
- Ollama 仍不支持音频输入(官方 issue 正在讨论中),而 Qwen3‑Omni的核心卖点涉及音频/视频输入与语音输出,因此即便未来有非官方 GGUF,也跑不全功能。(GitHub)
- 如需“先用上”:推荐 vLLM/Transformers 或官方/社区 Docker;若一定要走 Ollama,只能退而求其次:用 Qwen3(文本版)GGUF 在 Ollama 跑文字对话(不含音频/视频/TTS)。(Hugging Face)
一、Qwen3‑Omni 是什么(1 分钟认识)
原生全模态:不是外挂视觉/语音,而是在预训练/后训练阶段做混合多模态联合训练;官方称在 36 个音频/视听基准中 22 项达 SOTA、32 项开源 SOTA;同时文本/图像单模态性能不回退。(Hugging Face)
多语种:文本覆盖 119 种语言;语音输入 19 种、语音输出 10 种。(Hugging Face)
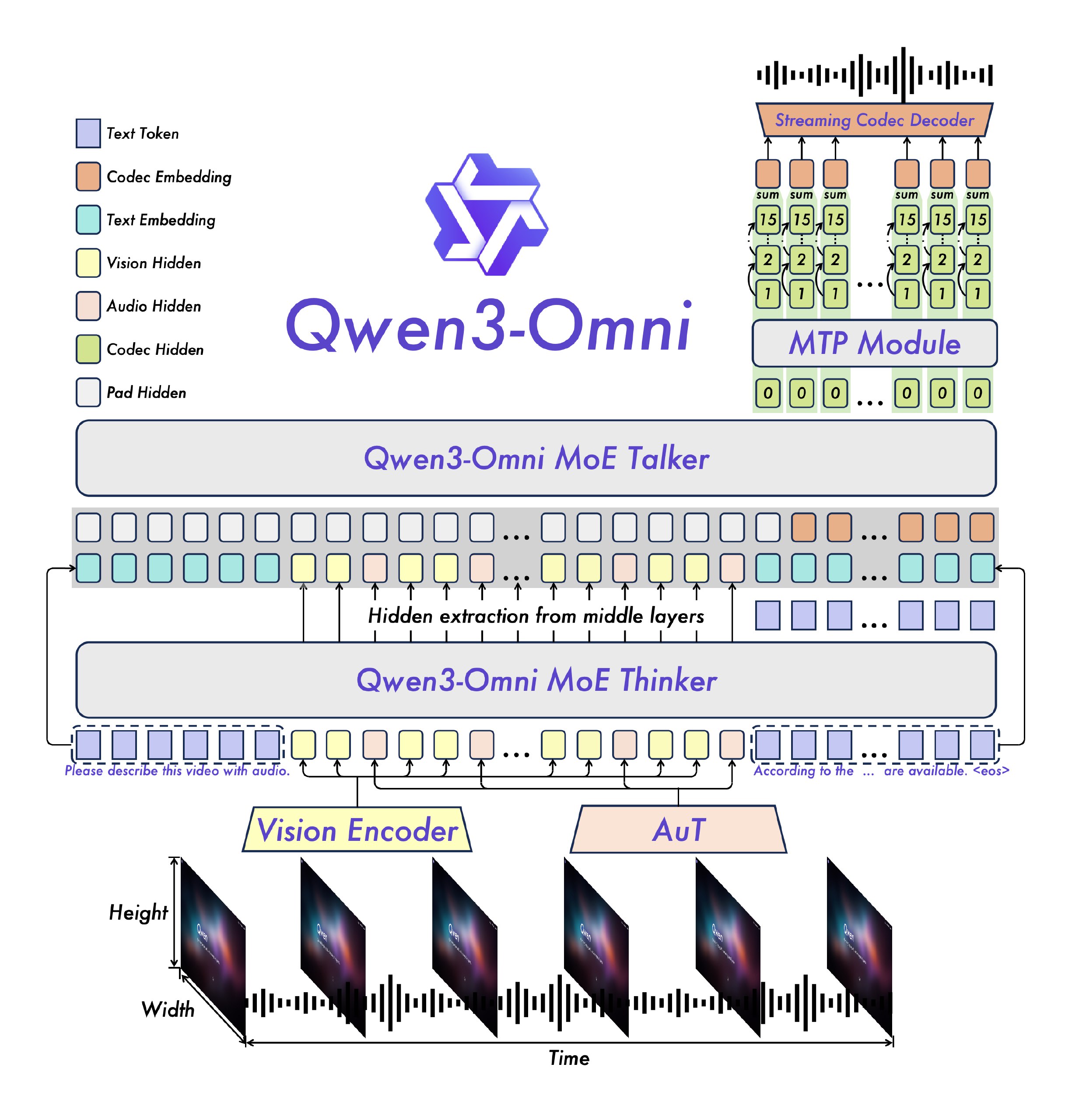
架构:Thinker–Talker(思考器+说话器)解耦设计,低延迟流式交互,适合实时语音对话与视听理解。(Hugging Face)
三种变体:
- Instruct:多模态输入,文本+语音输出(最完整)。
- Thinking:偏复杂推理,仅文本输出。
- Captioner:音频精细描述专项。(Hugging Face)
开源与发布:模型卡与 Demo 已在 Hugging Face 上线;媒体报道也确认“开放可下载、Apache‑2.0 许可、亦有 API 形态”。(Hugging Face)
二、在线体验入口(官方资源)
- Qwen3‑Omni Demo(HF Space):支持文本/图片/音频/视频输入的交互演示。(Hugging Face)
- Qwen3‑Omni Captioner Demo(HF Space):对任意音频生成精细描述。(Hugging Face)
- Qwen3‑Omni 模型卡(Instruct / Thinking / Captioner):含 QuickStart、Transformers/vLLM 用法与 Cookbook。(Hugging Face)
- Qwen Chat(chat.qwen.ai):在线聊天总入口(可关注是否开放 Omni 选项)。(Hugging Face)
- (可选)阿里云 API(ModelStudio/百炼):媒体报道指向了 API 形态与“更快的 Flash 版本”。(Venturebeat)
三、本地部署教程(推荐:vLLM / Transformers 路线)
说明:以下方案可完整获得 Qwen3‑Omni 的多模态输入与语音输出能力;Ollama 目前无法实现同等能力,详见下节判定。
方案 A:Transformers 直跑(Linux + NVIDIA)
适用:先验证功能、离线批处理、脚本化调用。
环境要求:Python 3.10+、CUDA 驱动、ffmpeg、显存建议 ≥ 40GB(Instruct 开启 Talker 时更高);以官方模型卡为准。(Hugging Face)
- 安装依赖(Transformers 需从源码装;官方模型卡明确说明):
1 | # 建议新建虚拟环境;如已安装 transformers,先卸载或直接用新环境 |
(以上步骤均来自官方模型卡“Transformers Usage”段落。)(Hugging Face)
- 下载权重(如需离线环境):
1 | pip install -U "huggingface_hub[cli]" |
(模型卡提供 Hugging Face 与 ModelScope 两种下载方式。)(Hugging Face)
- 最小示例(文本+图像+音频输入,文本+语音输出):
1 | from transformers import Qwen3OmniMoeForConditionalGeneration, Qwen3OmniMoeProcessor |
(完整代码片段与可切换发声人等选项,见模型卡。)(Hugging Face)
技巧:如暂不需要语音输出,可
model.disable_talker()节省约 10GB 显存;或在generate时return_audio=False,先拿到更快的文本结果。(Hugging Face)
方案 B:vLLM 高吞吐服务(推荐生产/多并发)
适用:在线推理服务、与 OpenAI API 兼容接入、批处理吞吐。
要点:官方模型卡提供了vLLM 用法,当前需从特定分支安装(包含多模态与音频输出支持的改动)。(Hugging Face)
- 安装 vLLM(根据模型卡给出的步骤):
1 | git clone -b qwen3_omni https://github.com/wangxiongts/vllm.git |
(以上命令与限制说明均来自 Qwen3‑Omni 模型卡“vLLM Usage”。)(Hugging Face)
- 代码示例(vLLM 推理,含多模态数据装载):模型卡已给出
LLM(... limit_mm_per_prompt=...)的完整示例,可直接复制。(Hugging Face)
补充:vLLM 官方 Docker 提供 OpenAI 兼容服务镜像(通用)。如要跑 Omni,仍建议按模型卡说明从源码装含多模态支持的分支,或使用官方后续提供的镜像。(vLLM)
四、(你最关心)能不能用 Ollama 从 Hugging Face 直接部署 Qwen3‑Omni?
结论(基于检索)
当前不可行(至少不具备“全模态+语音输出”的同等能力),原因有三:
- Ollama 只支持 GGUF(llama.cpp 系列)直接拉取 Hugging Face 模型:官方文档明确“可用任何 GGUF 模型,一条命令跑起”。而 Qwen3‑Omni 在 Hugging Face 发布的是
safetensors(Transformers/vLLM 生态),非 GGUF。(Hugging Face) - Ollama 目前不支持音频输入(官方 Feature Request 正在排期/讨论),这意味着即便日后出现社区 GGUF 转换,也无法在 Ollama 内实现 Qwen3‑Omni 的音频/视频输入与语音输出闭环。(GitHub)
- Qwen3‑Omni 为 30B MoE + 多模态 + Talker/TTS 的复杂栈;Ollama 虽已支持部分 MoE 文本模型与图像输入,但音频/视频与 TTS仍缺位。(Ollama)
对比参考:Qwen 团队早前的 Qwen2.5‑Omni 有社区 GGUF 转换,但 llama.cpp 侧也注明不支持视频输入与音频生成(仅文本/图像/音频输入部分特性),并且这属于 llama.cpp 生态,非 Ollama 官方全功能支持。(Hugging Face)
退一步的折中做法(两条路)
路 A|文本先行(Ollama):在 Ollama 直接运行 Qwen3(文本版)GGUF,即可完成“思维/非思维”两种文本对话能力的本地部署,但不含音频/视频/TTS。示例:
1
2# 直接拉取官方库中的 Qwen3(示例 8B GGUF)
ollama run hf.co/Qwen/Qwen3-8B-GGUF:Q4_K_M(Ollama + HF GGUF 的“hf.co/用户名/仓库[:量化标签]”写法,见 Hugging Face 官方文档;Qwen3 GGUF 由官方提供。)(Hugging Face)
路 B|全功能优先(推荐):按上文 vLLM/Transformers 路线部署 Qwen3‑Omni,原生支持音频/视频输入与语音输出,随后在业务层用 OpenAI 兼容接口 接入你已有的应用。(Hugging Face)
五、面向生产落地的实操清单
- 在线入口:Hugging Face Qwen3‑Omni Demo 与 Captioner Demo,用于业务前评估;模型卡含 Cookbook 与多模态日志。(Hugging Face)
- 本地/私有化:优先 vLLM / Transformers;如需容器化,可关注 qwenllm/qwen3‑omni DockerHub(官方或社区镜像),以及 vLLM 官方镜像。(vLLM)
- 接口适配:vLLM 提供 OpenAI 兼容服务端,便于与你现有 SDK/微服务集成。(vLLM)
- 硬件建议:Instruct(含 Talker/TTS)显存需求较高,可先在开发机关闭语音输出(
disable_talker),验证通过后再上 A/H 系列服务器或多卡并行。(Hugging Face)
六、常见问题(FAQ)
Q1:我就想用 Ollama,能不能“把 Omni 转成 GGUF 再跑”?
短期看难度很高:
- 需要可靠的 GGUF 转换(MoE + 多模态编码器 + Talker TTS 栈);
- Ollama 目前不支持音频输入,即使加载成功也跑不出 Omni 的关键价值(听+说)。(GitHub)
因此建议把 Ollama 用于文本类 Qwen3 或其它文本/图像模型,把 Omni 的多模态与语音输出交给 vLLM/Transformers 生态。(Hugging Face)
Q2:有没有“官方在线文档/报道”证明 Qwen3‑Omni 已开源并可在线访问?
有。Hugging Face 上线了 Qwen3‑Omni 集合与模型卡与 Demo;媒体也报道了发布与 API 形态。(Hugging Face)
Q3:我只要“听写/转写/翻译”,必须用 Instruct 吗?
不必须。官方还提供了 Captioner(音频精细描述)与 Thinking(偏推理,仅文本输出)两个变体,可按任务选型并兼顾显存与吞吐。(Hugging Face)
七、可直接复制的部署脚本片段
A. Transformers 直跑(Instruct,含 TTS)
1 | # 环境准备(建议新环境) |
(随后按上文 Python 代码示例推理。)(Hugging Face)
B. vLLM 服务(OpenAI 兼容;多并发)
(按模型卡“vLLM Usage”安装分支版本)
1 | git clone -b qwen3_omni https://github.com/wangxiongts/vllm.git && cd vllm |
(服务化与多模态输入示例见模型卡给出的 LLM(...) 代码段。)(Hugging Face)
C.(折中)Ollama 文本版 Qwen3
1 | # 直接跑 Qwen3 GGUF(文本对话,不含音频/视频/TTS) |
(写法来自 Hugging Face《Use Ollama with any GGUF model》;Qwen3 GGUF 由官方提供。)(Hugging Face)
参考与来源
- Qwen3‑Omni 模型卡与 QuickStart(含 Transformers 与 vLLM 用法、Cookbook、语音输出参数等)。(Hugging Face)
- Hugging Face 集合与在线 Demo(Qwen3‑Omni Demo / Captioner Demo)。(Hugging Face)
- 媒体报道(发布与 API 形态)。(Venturebeat)
- Ollama × Hugging Face 文档(GGUF 限定)。(Hugging Face)
- Ollama 音频输入功能请求(尚未支持)。(GitHub)
- Qwen3 在 Ollama 的文本模型库(可作为折中方案)。(Ollama)
写在最后
- “HF 下载 → Ollama 部署 Qwen3‑Omni”路线,当前结论是:不可行(缺 GGUF,且 Ollama 不支持音频输入/语音输出)。如果你接受文本优先,可以用 Qwen3 GGUF 在 Ollama 起服务;如果你要完整全模态与 TTS,请照本文给的 Transformers/vLLM 步骤执行。(Hugging Face)








