





一行代码本地运行 AI 模型
文章摘要
神人GPT
Ollama

一行代码下载运行模型
Ollama 运行代码
- 运行并与 Llama 2 交互:
1 | ollama run llama2 |
- 模型库:
Ollama 支持一系列模型,可以在 [invalid URL removed] 下载。
- 自定义模型:
从 GGUF 导入:
- 创建名为
Modelfile的文件,其中包含FROM指令,指定要导入的模型的本地文件路径。 - 创建模型:
1
ollama create example -f Modelfile
- 运行模型:
1
ollama run example
- 创建名为
从 PyTorch 或 Safetensors 导入:
请参阅导入模型的 指南:URL ollama import model ON Hugging Face ollama.ai 了解更多信息。
- 自定义提示:
1 | ollama pull llama2 |
LMStudio
无需代码下载运行模型,自带聊天页面
Open WebUI
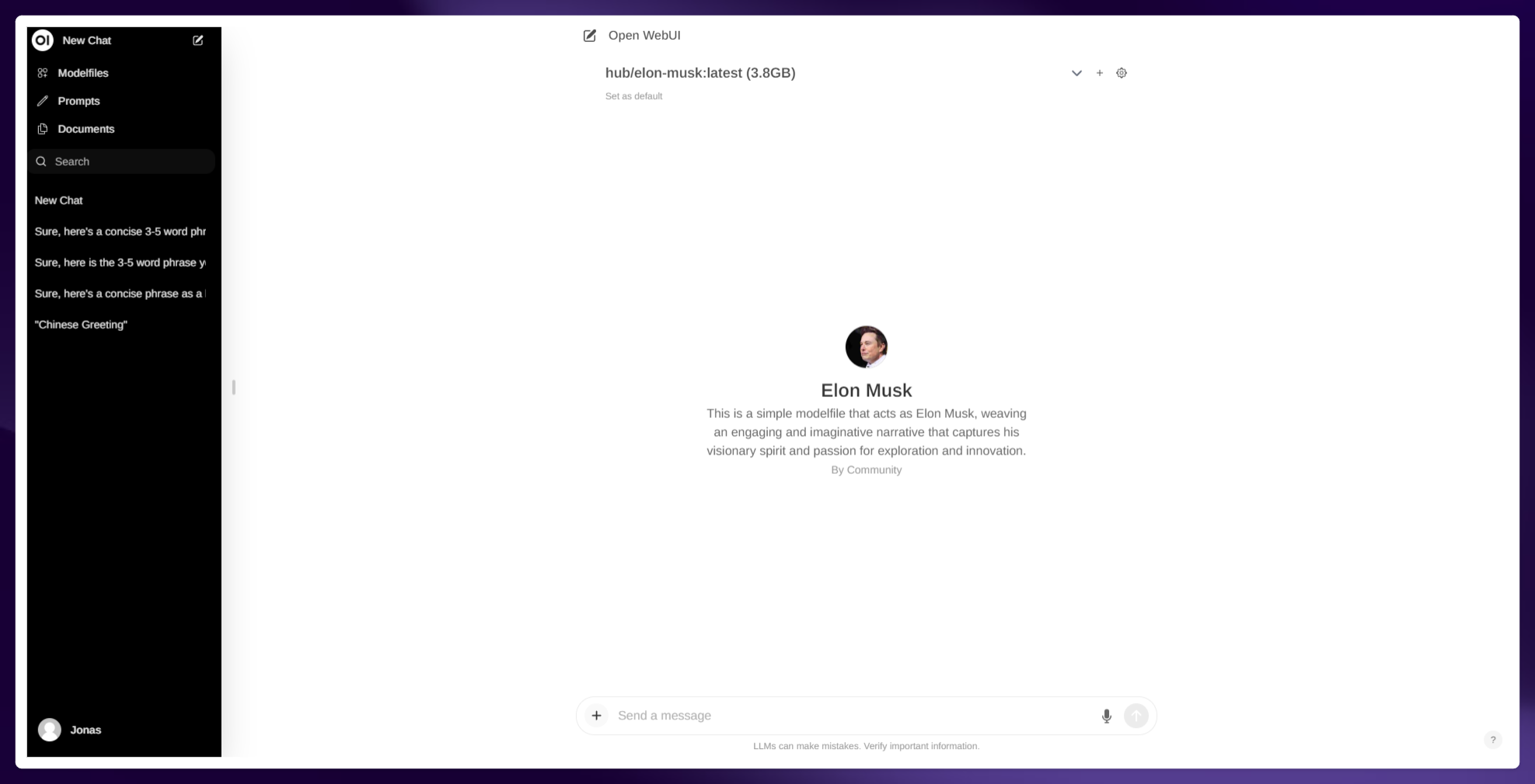
前端页面
https://github.com/open-webui/open-webui
docker 拉取并链接本地 Ollama
**使用 Docker 快速启动 **
使用 Docker 安装 Open WebUI 时,请务必在 Docker 命令中包含 -v open-webui:/app/backend/data 参数。这一步至关重要,因为它可以确保正确挂载数据库并防止数据丢失。
如果 Ollama 在您的计算机上,请使用以下命令:
1 | docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main |
如果 Ollama 在另一台服务器上,请使用以下命令:
要连接到另一台服务器上的 Ollama,请将 OLLAMA_API_BASE_URL 更改为服务器的 URL:
1 | docker run -d -p 3000:8080 -e OLLAMA_API_BASE_URL=https://example.com/api -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main |
安装完成后,您可以通过 http://localhost:3000 访问 Open WebUI。尽情使用吧!


评论 ()


这是我的博客 / This is my Blog
神烦老狗
只有迎风,风筝才能飞得更高。




